4.1 Archivos log del SGBD
Cuando trabajas frente al ordenador, navegas en tu
tablet u operas una página web desde un servidor, tienen lugar numerosos
procesos que pasan inadvertidos ante cualquier usuario. En caso de que se
presenten problemas, se produzcan errores o quieras conocer exactamente qué
acciones ejecutan los sistemas operativos o los diferentes programas o
servicios, puedes acceder a los llamados archivos log, en español ficheros de
registro. Estos “logs” son gestionados por prácticamente todas las
aplicaciones, servidores, bases de datos y sistemas de manera automática y
permiten controlar (de forma centralizada) todos los procesos relevantes.
En general, los ficheros log no suelen evaluarse
frecuentemente, pues cumplen una función similar a la de un registrador de
vuelo que es inspeccionado solo en caso de emergencia. Como consecuencia del
registro detallado de datos de los logs, estos son una fuente primordial a la
hora de analizar errores de programa o del sistema, así como para determinar el
comportamiento de los usuarios. Esto no solo resulta interesante para los
fabricantes de software, sino también para propietarios de páginas web, quienes
pueden acceder a información interesante desde los archivos de registro del
servidor web.

4.2 Definición de los modos de operación de un
SGBD. (alta, baja, recovery) y comandos de Activación.
La vida de todo archivo comienza
cuando se crea y acaba cuando se borra. Durante su existencia es objeto de
constante procesamiento, que con mucha frecuencia incluye acciones de consulta
o búsqueda y de actualización. En el caso de la estructura archivos,
entenderemos como actualización, además de las operaciones, vistas para
vectores y listas enlazadas, de introducir nuevos datos (altas) o de eliminar
alguno existente (bajas), la modificación de datos ya existentes, (operación
muy común con datos almacenados). En esencia, es la puesta al día de los datos
del archivo.
Una operación de alta en un
archivo consiste en la adición de un nuevo registro. En un archivo de
empleados, un alta consistirá en introducir los datos de un nuevo empleado.
Para situar correctamente un alta, se deberá conocer la posición donde se desea
almacenar el registro correspondiente: al principio, en el interior o al final
de un archivo.
El algoritmo de ALTAS debe
contemplar la comprobación de que el registro a dar de alta no existe
previamente. Una baja es la acción de eliminar un registro de un archivo. La
baja de un registro puede ser lógica o física. Una baja lógica supone el no
borrado del registro en el archivo. Esta baja lógica se manifiesta en un
determinado campo del registro con una bandera, indicador o “flag” -carácter *.
$, etc.,-, o bien con la escritura o rellenado de espacios en blanco en el
registro dado de baja.
v
Altas
La operación de dar de alta un
determinado registro es similar a la de añadir datos a un archivo. Es
importante remarcar que en un archivo secuencial sólo permite añadir datos al
final del mismo.
En otro caso, si se quiere
insertar un registro en medio de los ya presentes en el archivo, sería
necesaria la creación nueva del archivo.
El algoritmo para dar de alta un
registro al final del fichero es como sigue:
algoritmo altas
leer registro de alta
inicio
abrir archivo para añadir
mientras haya más registros hacer
{algunos lenguajes ahorran este bucle}
leer datos del registro
fin_mientras
escribir (grabar) registro de alta
en el archivo
cerrar archivo
fin
v
Bajas
Existen dos métodos para dar de
baja a un registro en un archivo secuencial, donde no es fácil eliminar un
registro situado en el interior de una secuencia: Para ello podemos seguir dos
métodos:
1.
Utilizar
y por tanto crear un segundo archivo auxiliar transitorio, también secuencial,
copia del que se trata de actualizar. Se lee el archivo completo registro a
registro y en función de su lectura se decide si el registro se debe dar de
baja o no. En caso afirmativo, se omite la escritura en el archivo auxiliar. Si
el registro no se va a dar de baja, este registro se reescribe en el archivo
auxiliar.
Tras terminar la lectura del
archivo original, se tendrán dos archivos: original (o maestro) y auxiliar. El
proceso de bajas del archivo concluye borrando el archivo original y cambiando
el nombre del archivo auxiliar por el del inicial.
2.
Guardar
o señalar los registros que se desean dar de baja con un indicador o bandera
que se guarda en un array; de esta forma los registros no son borrados
físicamente, sino que son considerados como inexistentes.
Inevitablemente, cada cierto
tiempo, habrá que crear un nuevo archivo secuencial con el mismo nombre, en el
que los registros marcados no se grabarán.
v
Propósito de Backup y Recuperación
Como administrador de copia de
seguridad, la tarea principal es diseñar, implementar y gestionar una
estrategia de backup y recuperación. En general, el propósito de una estrategia
de recuperación de copia de seguridad y es para proteger la base de datos
contra la pérdida de datos y reconstruir la base de datos después de la pérdida
de datos. Normalmente, las tareas de administración de seguridad son las
siguientes:
·
Planificación
y probar las respuestas a diferentes tipos de fallas.
·
Configuración
del entorno de base de datos de copia de seguridad y recuperación.
·
La
creación de un programa de copia de seguridad
·
Seguimiento
de la copia de seguridad y entorno de recuperación
·
Solución
de problemas de copia de seguridad
·
Para
recuperarse de la pérdida de datos en caso de necesidad
Como administrador de copia de
seguridad, es posible que se le pida que realice otros deberes que se
relacionan con copia de seguridad y recuperación:
·
La
preservación de datos, lo que implica la creación de una copia de base de datos
para el almacenamiento a largo plazo
·
La
transferencia de datos, lo que implica el movimiento de datos de una base de
datos o un host a otro.
v
De Protección de Datos
Como administrador de copia de
seguridad, su trabajo principal es hacer copias de seguridad y vigilancia para
la protección de datos. Una copia de seguridad es una copia de los datos de una
base de datos que se puede utilizar para reconstruir los datos. Una copia de
seguridad puede ser una copia de seguridad física o una copia de seguridad
lógica.
Copias de seguridad físicas son
copias de los archivos físicos utilizados en el almacenamiento y la
recuperación de una base de datos. Estos archivos incluyen archivos de datos,
archivos de control y los registros de rehacer archivados. En última instancia,
cada copia de seguridad física es una copia de los archivos que almacenan
información de base de datos a otra ubicación, ya sea en un disco o en medios
de almacenamiento fuera de línea, tales como cinta.
Copias de seguridad lógicas
contienen datos lógicos, como tablas y procedimientos almacenados. Puede
utilizar Oracle Data Pump para exportar los datos a archivos lógicos binarios,
que posteriormente puede importar a la base de datos.
Clientes de línea de comandos La
bomba datos expdp y impdp utilizan el DBMS_DATAPUMP y DBMS_METADATA PL / SQL
paquetes.
Copias de seguridad físicas son la
base de cualquier estrategia de recuperación de copia de seguridad sólida y. Copias
de seguridad lógicas son un complemento útil de las copias de seguridad físicas
en muchas circunstancias, pero no son suficiente protección contra la pérdida
de datos y sin respaldos físicos.
A menos que se especifique lo
contrario, la copia de seguridad término tal como se utiliza en la copia de
seguridad y la documentación de recuperación se refiere a una copia de
seguridad física. Copia de seguridad de una base de datos es el acto de hacer
una copia de seguridad física. El enfoque en la copia de seguridad y
recuperación de documentación está casi exclusivamente en copias de seguridad
físicas.
4.3 Índices, reorganización y reconstrucción.
Manejo
de índices
El
índice de una base de datos es una estructura alternativa de los datos en una
tabla. El propósito de los índices es acelerar el acceso a los datos mediante
operaciones físicas más rápidas y efectivas. En pocas palabras, se mejoran las
operaciones gracias a un aumento de la velocidad, permitiendo un rápido
acceso a los registros de una tabla en una base de datos. Existen diferentes
tipos de índices algunos de ellos son:
Índices
agrupados: definen el orden en que almacenan las filas de la tabla (nodos
hoja/página de datos de la imagen anterior). La clave del índice agrupado es el
elemento clave para esta ordenación; el índice agrupado se implementa como una
estructura de árbol b que ayuda a que la recuperación de las filas a partir de
los valores de las claves del índice agrupado sea más rápida. Debemos tener en
cuenta: Columnas selectivas, columnas afectadas en consultas, Columnas
accedidas "secuencialmente", Columnas implicadas en JOIN, GROUP BY y
el Acceso muy rápido a filas: lookups
Índices
no agrupados: tienen la misma estructura de árbol b que los índices
agrupados, con algunos matices; como hemos visto antes, en los índices
agrupados, en el último nivel del índice (nivel de hoja) están los datos; en
los índices no-agrupados, en el nivel de hoja del índice, hay un puntero a la
localización física de la fila correspondiente en el índice agrupado.
Índices
compuestos: es un índice de varias columnas de una tabla. Las columnas de
un índice compuesto que deben aparecer en el orden que tenga más sentido para
las consultas que recuperar datos y no necesita ser adyacente en la tabla.
Índices
descendientes: Este tipo de índice almacena los datos en una columna o
columnas de concreto en orden descendente.
Perder
y duplicar índices
La
primera cosa a ver, en el contexto de mantenimiento de índice, es
identificar y crear índices perdidos. Estos son índices que han sido
recomendados y sugeridos por el Motor SQL Server para mejorar el rendimiento de
nuestras consultas.
Otra
área para concentrarse es la duplicación de índices. Es peor tomar tiempo
revisando las columnas que están participando en cada índice en tu base de
datos, que es retornada al consultar los sistemas de objetos sys.index_columns y sys.indexes
descritos en el artículo previo, e identificar los índices duplicados
que son creados en las mismas exactas columnas cuando se remueve las mismas.
Recuerda el costo de los índices en la modificación de información y las operaciones
de mantenimiento y que puede llegar a la degradación del rendimiento.
Tablas
de montón
Las
tablas de montón son tablas que contienen índices no Agrupados. Esto significa
que las filas de información en la tabla de montón, no están almacenadas en
ningún orden particular en cada página de información. Además, no hay un orden
particular para controlar la secuencia de páginas de información, que no está
unida en una
lista conectada. Como resultado, recuperar
información de insertar o modificar en la tabla montón será muy lento y puede
ser fragmentado más fácilmente.
Necesitas
primero identificar las tablas montón en tu base de datos y concentrarte solo
en las tablas grandes, ya que el Optimizador de Consultas de SQL Server no se
beneficiará de los índices creados en tablas más pequeñas. Tablas de montón
pueden ser detectadas al consultar objetos sys.indexes system, en conjunción
con otros sistemas de vistas de catálogo, para recuperar información
significante, como se muestra en el script T-SQL de abajo:
|
1 2 3 4 5 6 7 8 |
SELECT
OBJECT_NAME(IDX.object_id) Table_Name ,
IDX.name Index_name , PAR.rows NumOfRows , IDX.type_desc TypeOfIndex FROM sys.partitions PAR INNER JOIN sys.indexes IDX
ON PAR.object_id = IDX.object_id AND PAR.index_id = IDX.index_id
AND IDX.type = 0 INNER JOIN sys.tables TBL ON TBL.object_id =
IDX.object_id and TBL.type ='U' |
De
los resultados de consulta anterior, identifica las tablas de montón grandes y
crea un índice Agrupado en estas tablas para mejorar el
rendimiento de la lectura de las consultas de estas tablas. El resultado en
nuestro caso será como el mostrado abajo:

Índices no usados
En el
artículo previo, mencionamos dos modos de obtener el uso de la información
sobre índices de base de datos, el primero usando el sys.dm_db_index_usage_stats DMV
y el segundo modo usando el reporte standard Index Usage Statistics.
Índices no usados que no son usados en ninguna operación de búsqueda o escaneo,
o que son relativamente pequeños, o que son actualizados muchas veces deberían
ser removidos de tu tabla, ya que va a
degradar
la modificación de información y el rendimiento de operaciones de mantenimiento
de índice, en vez de mejorar el rendimiento de tus consultas.
El
mejor modo de lidiar con índices no usados es quitarlos. Pero antes de hacer
eso, asegúrate de que…
- El
índice no es un índice nuevamente creado
- Que
el sistema será usado en el futuro próximo
- Y
que el SQL Server no haya sido reiniciado recientemente
La
razón para esto es que los resultados de estos dos métodos serán actualizados
cada vez que el SQL Server reinicie y puede proveer información incompleta para
iniciar la eliminación del índice. En caso de un uso ineficiente de un índice
Agrupado, asegúrate de remplazarlo con otro y mantener la tabla como montón.
Arreglar
fragmentación de índice
En el
SQL Server, la mayor parte de las tablas son tablas transaccionales, que no son
estáticas pero son cambiantes en el tiempo. La fragmentación de índices ocurre
cuando el orden lógico de las páginas del índice, basadas en el valor clave, no
corresponde al orden físico dentro de la información del archivo. Hemos
discutido previamente que, debido a la inserción frecuente de la información y
modificación de operaciones, las páginas de índice serán divididas y
fragmentadas, cuando la página este llena, o que no entre el valor nuevo o
actualizado en el espacio libre actual, aumentando la cantidad de operaciones
del disco I/O para leer la información requerida.
Por
otro lado, configurando las opciones de creación de Fill Factor y pad_index con
los valores apropiados ayudará a reducir la fragmentación de índice y problemas
de división de página. Otras formas diferentes de obtener información de
fragmentación sobre la base de datos de índices se puede realizar de diferentes
formas, como consultar la función dinámica de
administración sys.dm_db_index_physical_stats y
el reporte standard Index Physical Statistics , que son
mencionados en detalle en el artículo previo.
La
desfragmentación de índice asegura que las páginas de índice sean contiguas,
proveyendo formas más rápidas y eficientes para acceder a la información, en
vez de leer de páginas esparcidas a través de páginas múltiples separadas.
El SQL
Server nos provee de diferentes formas de arreglar el problema de fragmentación
de índice. El primer método es usar el comando DBCC INDEXDEFRAG, que
desfragmenta el nivel hoja de un índice, seriamente un índice a la vez usando
un único hilo, de una forma que permite el orden físico a las páginas para corresponder
al orden lógico izquierdo-a –derecha en los nodos hoja, mejorando el
rendimiento de escaneo del índice. El comando DBCC INDEXDEFRAG es
una operación online que guarda bucles de corto término en el objeto de la base
de datos subyacente sin afectar ninguna consulta o actualización corriendo. El
tiempo requerido para desfragmentar un índice depende principalmente del nivel
de fragmentación donde un índice con pequeño porcentaje de fragmentación puede
ser desfragmentado más rápido que un índice nuevo pueda ser construido. Por
otro lado, un índice que es muy fragmentado, pueda tomar considerablemente más
tiempo en desfragmentar que reconstruir. Si el comando INDEXDEFRAG es detenido
en cualquier momento, todo el trabajo completado será retenido.
Asume
que tenemos el índice de abajo con un porcentaje de fragmentación igual a 99.72
%, como se muestra en la captura de pantalla de abajo, tomando de las
propiedades del índice:
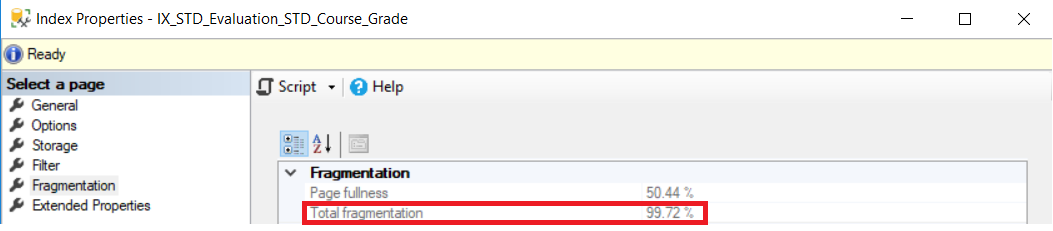
El
comando DBCC INDEXDEFRAG puede ser usado para desfragmentar todos los índices en
una base de datos específica, todos los índices en una tabla específica o
índice específico solo dependen de los parámetros provistos. El script de abajo
es usado para desfragmentar el índice previo que tiene un porcentaje alto de
fragmentación:
|
1 2 |
DBCC INDEXDEFRAG
(IndexDemoDB, 'STD_Evaluation',
IX_STD_Evaluation_STD_Course_Grade); GO |
El resultado retornado del comando,
muestra el número de páginas que son escaneadas, movidas y removidas durante el
proceso de desfragmentación, como se muestra abajo:
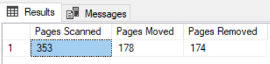
Verificando
el porcentaje de desfragmentación después de correr el comando DBCC
INDEXDEFRAG, el porcentaje de fragmentación se vuelve menos que el 1% mostrado
abajo:
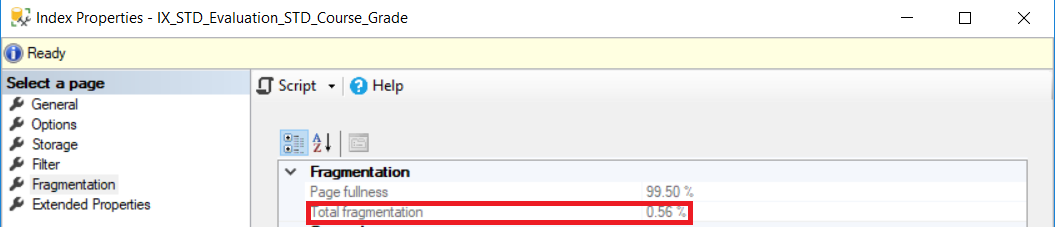
La
fragmentación de índice puede ser también resuelto al reconstruir y reorganizar
los índices SQL Server regularmente. Las operaciones de Reconstrucción de
índice remueven fragmentación al abandonar el índice y creándolo de nuevo,
desfragmentando todos los niveles de índice, compactando las páginas de índice
usando los valores de Fill Factor especificados en el comando reconstruir, o
usando el valor existente si no es especificado y actualizando las estadísticas
usando FULLSCAN de toda la información. Recuerda que reconstruir un índice
desactivado
lo
vuelve de nuevo a vida. La operación de reconstrucción de índice puede ser
realizada online, sin cerrar otras consultas cuando se usa el SQL Server
Enterprise edition, u offline al guardar bucles en los objetos de base de datos
durante la operación de reconstrucción. Además, la operación de índice
reconstruido puede usar paralelismos cuando se usa Enterprise edition. Por el
otro lado, si la operación de reconstrucción falló, una operación fuerte de
reducción será realizada. El índice puede ser reconstruido usando el comando
T-SQL ALTER INDEX REBUILD.
La
operación de Index Reorganize reordena físicamente las páginas
de nivel hoja del índice para corresponder con el orden lógico de los nodos
hoja. La operación de reorganización de índice será siempre realizado online.
Microsoft recomienda arreglar problemas de fragmentación de índice al
reconstruir el índice si el porcentaje de fragmentación excede el 30 %, donde
recomienda arreglar el problema de fragmentación de índice al reorganizar el
índice si el porcentaje de fragmentación de índice excede 5 % y menos de 30 %.
La operación de reorganización de índice usará un solo hilo, independientemente
del SQL Server Edition usado. Por otro lado, si la operación de reorganización
falla, va y para donde se quedó, sin retroceder la operación de reorganización.
El índice puede ser reorganizado usando el comando ALTER INDEX
REORGANIZE.
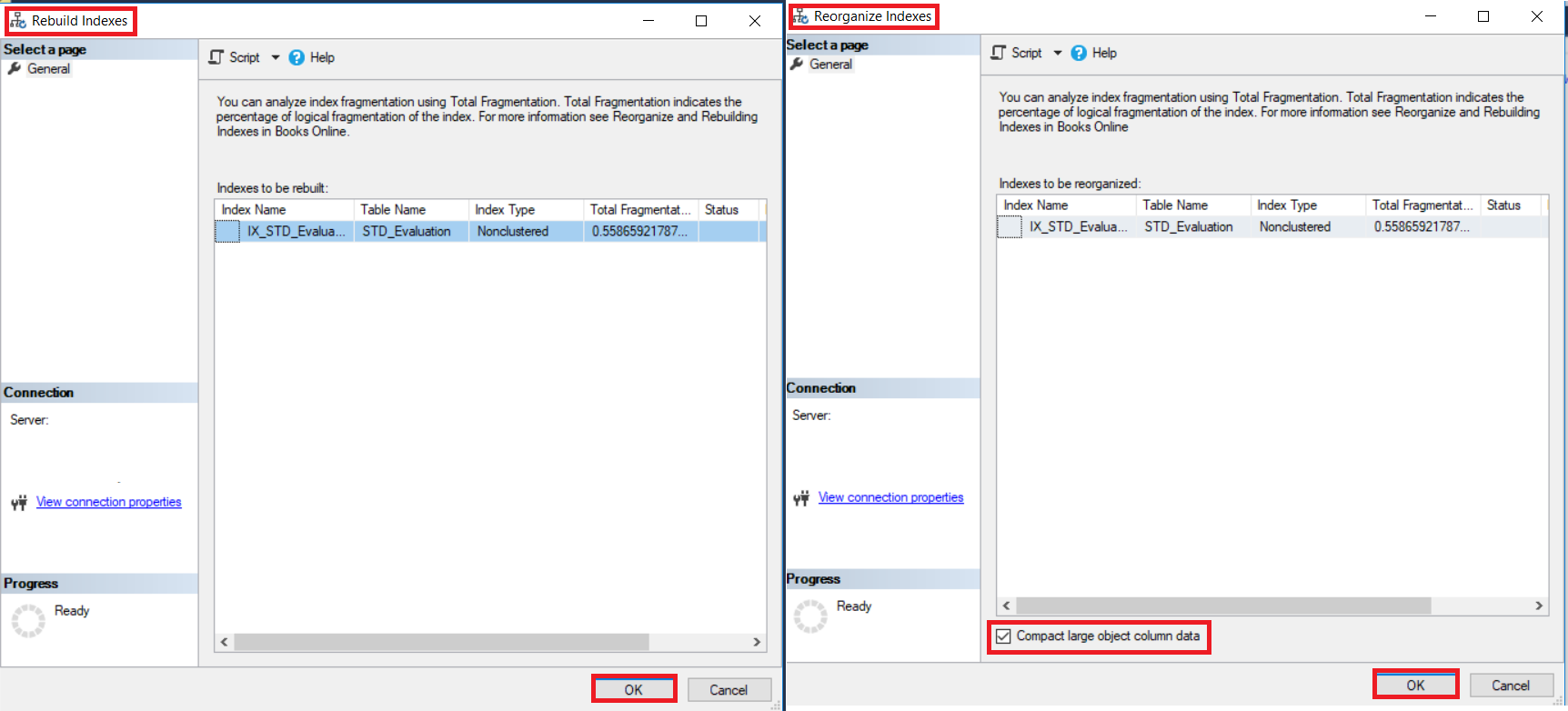
El
índice puede ser reconstruido o reorganizado usando el SQL Server Management
Studio al abrir los nodos de Índices bajo tu tabla, escoge el índice que
pretendes desfragmentar, haz clic derecho en ese índice y escoge la opción
Rebuild o Reorganize, basado en el porcentaje de fragmentación de ese índice,
como se muestra abajo:
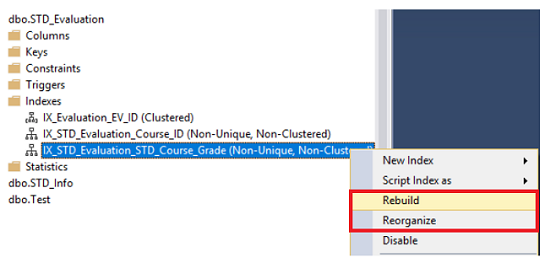
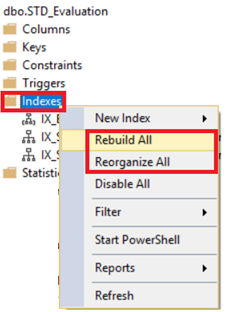
El SQL
Server te permite reconstruir o reorganizar todas las tablas de índices, al
hacer clic derecho en el nodo de índices bajo tu tabla y escoger la opción
Rebuild All o Reorganize All, como se muestra abajo:
La
ventana mostrada de reconstruir o reorganizar va a listar todas las tablas de
índices que van a ser desfragmentados usando esa operación, con el nivel de
fragmentación de cada índice, como se muestra en la captura de pantalla de
abajo:
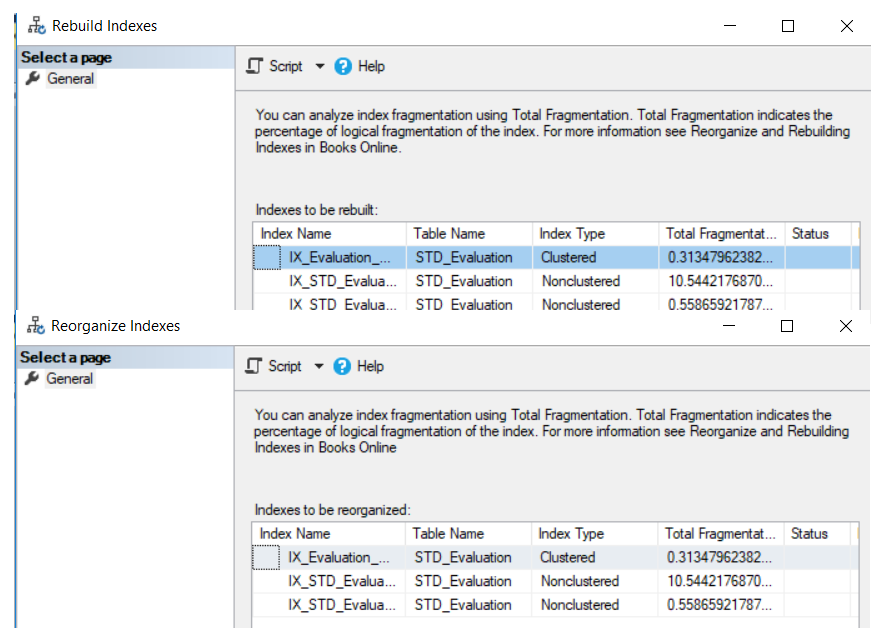
La
misma operación puede también ser realizada usando comandos T-SQL. Puedes
reconstruir el índice previo, usando el comando ALTER INDEX REBUILD T-SQL, con
la habilidad de configurar las diferentes opciones de creación de índice, como
el FILL FACTOR, ONLINE o PAD_INDEX, como se muestra abajo:
|
1 2 3 4 |
USE [IndexDemoDB] GO ALTER INDEX
[IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REBUILD
PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS =
ON) GO |
También,
el
índice puede ser reorganizado, usando el comando ALTER INDEX REORGANIZE T- de
abajo:
|
1 2 3 4 |
USE [IndexDemoDB] GO ALTER INDEX
[IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation]
REORGANIZE WITH ( LOB_COMPACTION = ON ) GO |
Puedes también organizar todas las tablas
de índices, al proveer la declaración ALTER INDEX REORGANIZE T-SQL con la
opción ALL, en vez de el nombre de índice, como la declaración T-SQL de abajo:
|
1 2 3 |
ALTER INDEX ALL ON
[dbo].[STD_Evaluation] REORGANIZE ; GO |
Y
reconstruir todos los índices de la tabla, al proveer la declaración ALTER
INDEX REBUILD T-SQL con la opción ALL, en vez del nombre del índice, como la
declaración T-SQL de abajo:
|
1 2 3 |
ALTER INDEX ALL ON
[dbo].[STD_Evaluation]
REBUILD WITH (PAD_INDEX =
OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
En SQL Server 2014, la nueva
funcionalidad fue introducida que nos permite controlar cómo es manejado el
mecanismo de bloqueo, que es requerido por la operación de
reconstrucción de índice online. Este mecanismo es llamado Managed Lock
Priority, que se beneficia de la nueva y definida fila de Baja Prioridad
que contiene los procesos con prioridades más bajas que aquellas esperando en
la fila de espera, dando al administrador de base datos la habilidad de manejar
las prioridades de espera.Mantenimiento las estadísticas de índice
Las
estadísticas de Índice son usadas por el Optimizador de consultas de SQL Server
para determinar si el índice será usado en la ejecución de la consulta.
Estadísticas obsoletas llevara al Optimizador de Consultas a seleccionar el
índice equivocado mientras se ejecuta la consulta. Desde el aspecto operativo
de sistema SQL Server, cuando se selecciona un índice, el Optimizador de
Consultas de SQL Server va a ignorar el índice si tiene un alto porcentaje de
fragmentación (como buscar en el costará más que el escaneo de tabla), los
valores de índice no son únicos, las estadísticas de índice están obsoletas o
el orden de las columnas en la consulta no corresponde al orden de las columnas
de índice clave.
Las
estadísticas de índice puedes ser actualizadas automáticamente por el Motor SQL
Server o manualmente usando el procedimiento sp_updatestats stored,
que corre UPDATE STATISTICS contra todas las tablas user-defined y tablas
internas en la actual base de datos, o usando el comando UPDATE
STATISTICS T-SQL, que puede ser usado para actualizar las estadísticas
de todas las tablas de índices o actualizar las estadísticas de un índice
específico en la tabla. La declaración T-SQL de abajo es usada para actualizar
las estadísticas de todos los índices bajo la tabla STD_Evaluation:
|
1 2 |
UPDATE STATISTICS
STD_Evaluation; GO |
Donde
la declaración T-SQL de abajo va a actualizar las estadísticas de solo
un índice, bajo esa tabla:
|
1 2 |
UPDATE STATISTICS
STD_Evaluation IX_STD_Evaluation_STD_Course_Grade; GO |
Puedes también actualizar las
estadísticas de toda la tabla de índices, al especificar el porcentaje de las
filas ejemplares, como se muestra en la declaración T-SQL de abajo:
|
1 2 |
UPDATE STATISTICS
STD_Evaluation WITH
SAMPLE 50 PERCENT; |
O forzarlo a escanear todas las filas de
la tabla durante la actualización de estadísticas de la tabla, usando la opción
FULLSCAN, mostrado abajo:
|
1 2 3 |
UPDATE STATISTICS
STD_Evaluation WITH
FULLSCAN, NORECOMPUTE; GO |
Automatizar
mantenimiento de índice SQL server
Hasta
este punto, nos hemos familiarizado en cómo tomar la decisión si vamos a
reconstruir o reorganizar un índice SQL Server, basados en el porcentaje de la
fragmentación, y cómo desfragmentar un índice específico o todas las tablas de
índice usando los métodos rebuild o reorganize. También revisamos la
importancia de rendimiento de diferentes tipos de tareas de mantenimiento de
índices regularmente, para poder permitir que el Optimizador de Consultas de
SQL Server considere estos índices para mejorar el rendimiento de las
diferentes consultas y minimizar los costos de estos índices en el sistema
general de base de datos.
Por
otro lado, realizar las tareas de mantenimiento de índices manualmente no es
una buena práctica, ya que estos operadores puedan tomar un largo tiempo que el
DBA no tendrá paciencia para esperar, además que el DBA no está siempre
disponible
para recordar correr estas tareas, lo cual puede llevar a acumular altos
porcentajes de fragmentación.
Hay
dos opciones para automatizar el mantenimiento de índices. La primera opción es
planificar un script personalizado de mantenimiento de índice, para
reconstruir, reorganizar, desfragmentar y actualizar las estadísticas basado en
el porcentaje de fragmentación usando el trabajo SQL Server Agent, que puede
ser tu propio script basado en el comportamiento de tu sistema y
requerimientos, o personalizar mi script flexible favorito Ola
Hallengren’s index maintenance que te provee de un gran número de opciones
que pueden entrar en un gran rango de sistemas de comportamientos.
La
segunda opción para automatizar las tareas de mantenimiento de índice es usando
los Rebuild Index, Reorganize Index and Update Statistics Maintenance Plans, de
los nodos de Management como se muestra abajo:
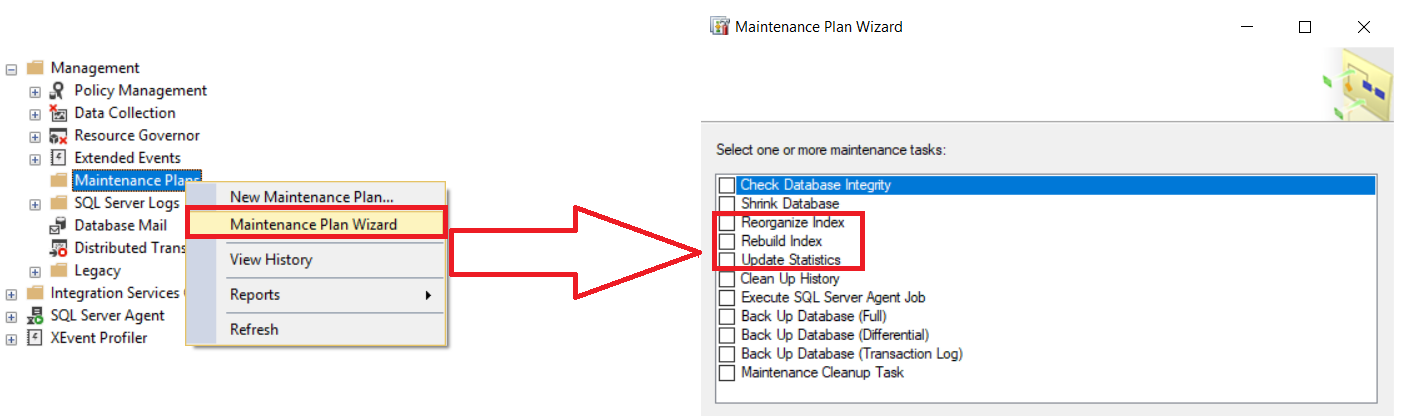
Necesitas
especificar el nombre de la base de datos o bases de datos que pretendes
realizar una tarea de mantenimiento de índices, con la habilidad de reducir
para realizar sobre una tabla específica y programar ese mantenimiento para ser
realizado durante las horas no pico, basados en la carga de trabajo que
especifica las ventanas de mantenimiento disponibles en tu compañía, tu
estructura de base de datos, cuán rápido la información es fragmentada y la
edición de SQL Server. Recuerda que el tiempo requerido para realiza las tareas
de mantenimiento puede ser disminuida al usar el Enterprise Edition, que te
permite realizar la operación de reconstrucción de índice online y usar planes
paralelos.
Usando
los SQL Server Maintenance Plans para automatizar las áreas de mantenimiento de
índices no es una opción preferida cuando se usa versiones SQL Server anterior
a 2016, debido a la falta de control en estas pesadas operaciones. Esto es
debido a que estas tareas de mantenimiento serán realizadas en todas las tablas
o índices de base de datos independientemente del porcentaje de fragmentación
de estos índices. Esas operaciones van a requerir una ventana de largo
manteamiento y va a consumir intensivamente los recursos del servidor cuando se
mantiene grandes bases de datos.
Empezando
del SQL Server 2016, nuevas opciones fueron añadidas a las tareas de
mantenimiento de índices que nos permiten realizar las tareas de Reconstruir
Índices y Reorganizar Índices, basados en el porcentaje de fragmentación del
índice, y otras opciones útiles para controlar el proceso de mantenimiento del
índice.
Las
siguientes capturas de pantalla resumen como podemos especificar los parámetros
de porcentaje de fragmentación para ambos planes de mantenimiento de
reconstrucción del índice y reorganización, y otras opciones de control como se
muestra abajo:
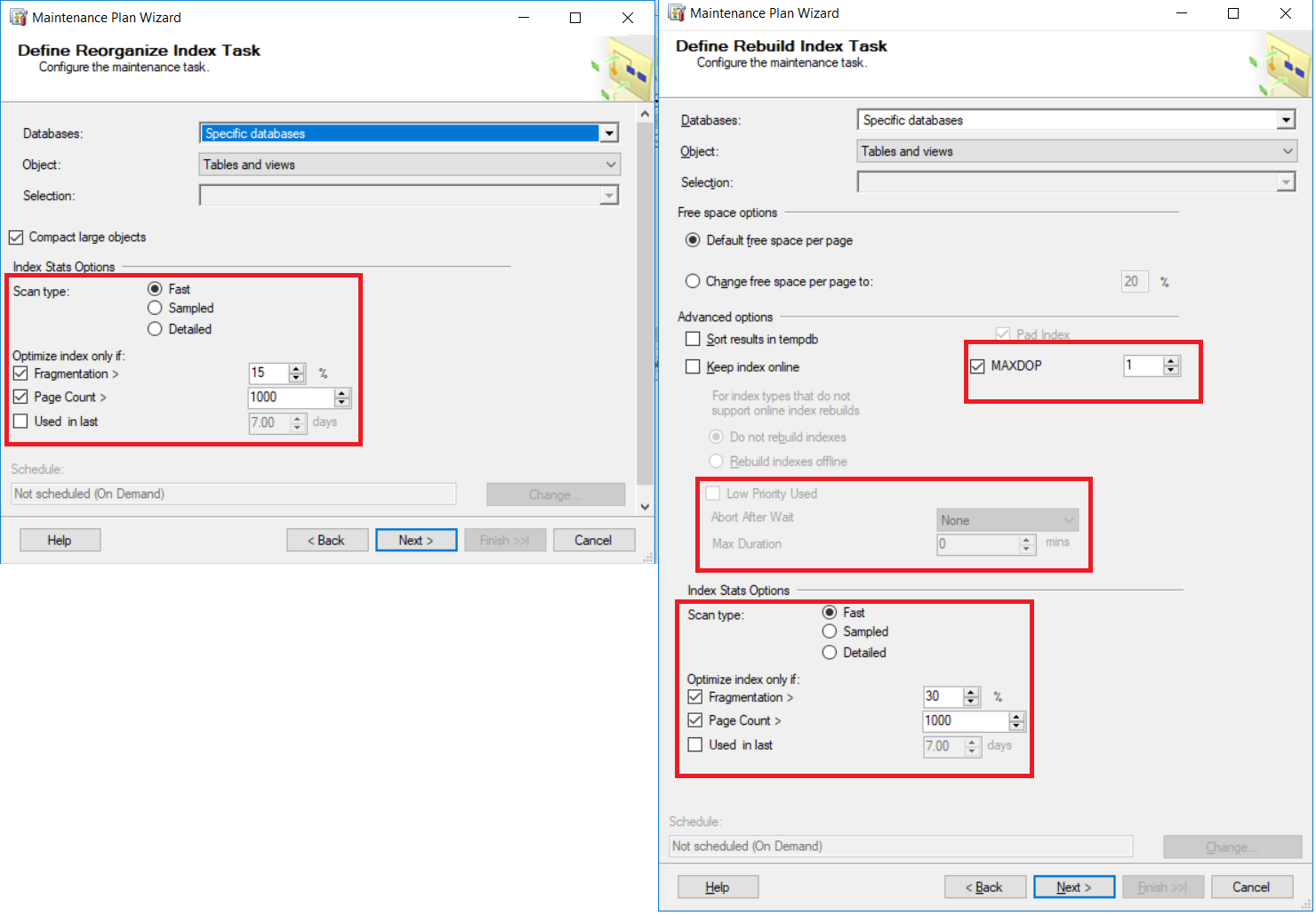
Requerimientos
de mantenimiento de Índices
Cuando
reconstruyes un índice, un espacio adicional temporal del disco es requerido
durante la operación para almacenar una copia del índice viejo, deshaciendo los
cambios realizados en caso de fallo, y para aislar la operación de
reconstrucción del índice online de los efectos de modificaciones hechas por
otras transacciones usando filas versionando y clasificando los valores de
índice clave. Si la opción SORT_IN_TEMPDB es habilitada, espacio tempdb, donde
entra el tamaño de índice, debería estar disponible para clasificar los valores
de índice. Esta opción hace más rápido el proceso de reconstrucción al separar
las transacciones del índice de las transacciones concurrentes del usuario, si
la base de datos tempdb está en una unidad de disco separada. Por otro lado, es
requerido espacio adicional permanente de disco para almacenar
la nueva estructura del índice.
Para
realizar operaciones de larga escala, como operaciones index Rebuild y
Reorganize, que pueden llenar el registro de transacción rápidamente, el archivo
de base de datos de registro de transacciones debería tener
suficiente espacio libre
para
almacenar las operaciones de transacciones de índices, que no serán truncadas
hasta que la operación es completamente exitosa, y cualquier transacción de
usuario concurrente realizado durante la operación de índice.
La
gran cantidad de registros de transacciones escritas en los archivos de
registros de base de datos de transacción durante las operaciones de
desfragmentación del índice requiere un tiempo más largo para copiar el archivo
de registro de transacción. Este efecto puede ser minimizado al realizar
registros copia de transacción más frecuentemente durante las operaciones de
mantenimiento o cambiando el modelo de recuperación de base de datos a SIMPLE o
BULK o LOGGED para minimizar el registro durante esa operación, si es
aplicable. Además, el costo de red extra será causado al mandar una gran
cantidad de registros de transacción a los servidores de Grupos de
Disponibilidad secundarios. Si un problema de red notable es causado durante
las operaciones de mantenimiento, puedes superar ese problema al pausar el
proceso de sincronización de información durante las operaciones de
mantenimiento de índice, si es aplicable
Reorganización
de índices
Un
factor clave para conseguir una E/S de disco mínima para todas las consultas de
bases de datos es asegurarse de que se creen y se mantengan buenos índices. Un
paquete puede usar la tarea Reorganizar índice para reorganizar los índices de
una base de datos individual o de varias bases de datos.
La
tarea Reorganizar índice encapsula la instrucción ALTER INDEX de Transact-SQL.
Si elige compactar datos de objetos grandes, la instrucción utiliza la cláusula
REORGANIZE WITH (LOB_COMPACTION = ON); en caso contrario, se establece
LOB_COMPACTION en OFF.
Fragmentación
de los Índices
La
fragmentación es consecuencia de los procesos de modificación de los datos
(instrucciones INSERT, UPDATE y DELETE) efectuados en la tabla y en los índices
definidos en la tabla.
Detección
de Fragmentación
El
primer paso para decidir qué método de desfragmentación se va a utilizar
consiste en analizar el índice para determinar el nivel de fragmentación. Si se
usa la función del sistema sys.dm_db_index_physical_stats, se puede detectar la
fragmentación de los índices de la base de datos thuban-homologada.
Reconstrucción
de índices
Se
debe examinar y determinar qué índices son susceptibles de ser reconstruidos.
Cuando un índice está descompensado puede ser porque algunas partes de éste han
sido accedidas con mayor frecuencia que otras.
Blevel
(branch level) es parte del formato del B-tree del índice e indica el
número de veces que Oracle ha tenido que reducir la búsqueda en ese índice. Si
este valor está por encima de 4 el índice deberá de ser reconstruido.
ALTER
INDEX <index_name> REBUILD;
Para
reconstruir una partición de un índice podríamos hacer los siguientes:
ALTER
INDEX <index_name> REBUILD PARTITION <nb_partition> NOLOGGING;
Comando
ALTER INDEX
Como hemos comentado esta sentencia se utiliza para cambiar o reconstruir un
Índice existente en la base de datos. Para reconstruir un Índice bastaría
con lazar la siguiente sentencia: ALTER INDEX REBUILD;
No hay comentarios.:
Publicar un comentario